How to export a plain-text conversation transcript for a sound file annotated with the Praat program
Mietta Lennes
30.12.2009
|
|
→ |
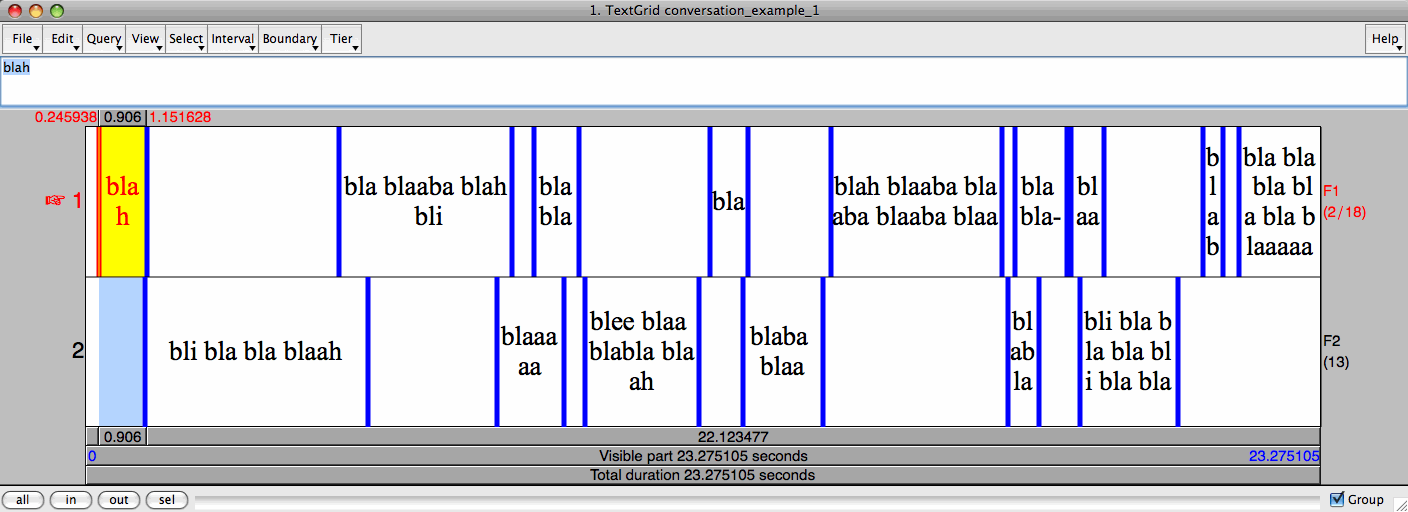
conversation_example_1 (Tue Dec 29 17:05:15 2009)
F1: blah
F2: bli bla bla blaah
F1: bla blaaba blah bli
F2: blaaaaa
F1: blabla
F2: blee blaa blabla blaah
F1: bla
F2: blaba blaa
F1: blah blaaba blaaba blaaba blaa
F2: blabla
F1: bla bla-
blaah
F2: bli bla bla bla bli bla bla
F1: blabl-
bla bla bla bla bla blaaaaah
|
Watch
the video
tutorial!
Please note: The Praat script described here is still being tested and may contain bugs! In case you believe the script is not working correctly or if you notice errors in the instructions below, I would be happy to receive suggestions for improvements by email.
However, I cannot provide further support for using or modifying the script.
Introduction
Once you have annotated an audio recording of conversational speech with the Praat program, you can use this Praat script
for exporting a transcript of the conversation from the TextGrid object into a plain text file. It is then easy to modify and use the transcript as a human-readable description of your material in presentations and publications.
The same Praat script can also be used for exporting any other annotations from Praat. However, the instructions below are based on a fictitious example of conversational speech.
Prerequisites: Exactly one TextGrid object must be selected in the Object list of the Praat program. Each speaker's utterances must be represented by the labeled intervals in one interval tier in the selected TextGrid object. Thus, the TextGrid object must contain at least as many IntervalTiers as there are participants in the conversation.
Result: a plain text file containing a skeletal CA style transcript with one utterance per line. Lines are saved in the order of their starting times within the TextGrid object. When speakers change, the code for the next speaker will appear at the beginning of the line. Utterances that are completely overlapped by a preceding utterance will appear in square brackets. The user may choose to insert the durations of pauses (in seconds) between lines, where applicable (pauses referring to those portions of the audio during which nobody is speaking). In addition, it is possible to insert the starting times of overlapping speech in relation to the end time of a preceding utterance (in seconds). Overlaps will appear in brackets like pause durations, but they will be represented as negative numbers. For instance, the overlap time (-0.20 s) would mean that the next utterance overlaps a previous speaker and it has started 0.2 seconds before the preceding utterance ended.
Why should you use Praat for transcribing conversational speech?
- With a little practise, it is easy and convenient to transcribe conversational speech with Praat, since it is possible to repeatedly listen to small portions of the audio file.
- When studying spoken language, it is important to be able to refer to the original recordings as required. By using the Praat script described below, the researcher may readily use both the audio material and the human-readable transcript in parallel.
- As the basic transcript has been created using Praat and as the start times of the original utterances can be inserted in the exported transcript, it is easy to find the desired portion in the audio file later.
- It is easy to quickly go back and listen to any desired portion of the original recording that has been annotated with Praat.
- Once a transcript has been created with Praat, it may encourage the researcher to apply different acoustic methods for measuring and illustrating conversational speech. For instance, it is possible to supplement a CA transcript with a detailed acoustic-phonetic analysis of a particular event within a conversation.
NB: In order to be able to correctly interpret the acoustic measurements, the audio signal must be of sufficiently good quality with reasonably little background noise and no overlapping speech. One must also know the acoustic method and the phonetic factors that may affect the result.
For instance, the Pitch analysis, related to speech melody and intonation, may be misinterpreted unless one knows the limitations of the analysis and defines the analysis parameters in an optimal way.
- In addition to utterance tiers, it is possible to enrich the annotation of the speech material with any number of other annotation tiers. One may wish to describe, e.g., paralinguistic features, voice quality, or miscellaneous comments as separate annotation tiers. In case a more detailed acoustic-phonetic analysis is required, one may insert tiers for words and individual speech sounds that may be annotated at the desired locations. Such detailed segmentation may be utilized for defining and saving the exact points for acoustic measurements, or for drawing pictures.
- All changes and corrections should be made in the original TextGrid file with Praat. With the script, one can produce new transcript versions as required.
Example
Imagine that the following conversation with two speakers (F1 and F2) has been annotated with Praat:
When the annotations above are exported into a plain text file with the Praat script, this is what the result would look like:
Plain transcript:
conversation_example_1 (Tue Dec 29 17:05:15 2009)
F1: blah
F2: bli bla bla blaah
F1: bla blaaba blah bli
F2: blaaaaa
F1: blabla
F2: blee blaa blabla blaah
F1: bla
F2: blaba blaa
F1: blah blaaba blaaba blaaba blaa
F2: blabla
F1: bla bla-
blaah
F2: bli bla bla bla bli bla bla
F1: blabl-
bla bla bla bla bla blaaaaah
|
Full transcript with the start times of the utterances, pause durations and overlap durations:
conversation_example_1 (Tue Dec 29 16:45:22 2009)
[0.25 s] F1: blah
(-0.04 s)
[1.12 s] F2: bli bla bla blaah
(-0.54 s)
[4.77 s] F1: bla blaaba blah bli
(-0.29 s)
[7.74 s] F2: blaaaaa
(-0.57 s)
[8.44 s] F1: blabla
(0.10 s)
[9.40 s] F2: blee blaa blabla blaah
(0.20 s)
[11.75 s] F1: bla
(-0.10 s)
[12.38 s] F2: blaba blaa
(0.16 s)
[14.04 s] F1: blah blaaba blaaba blaaba blaa
(0.11 s)
[17.37 s] F2: blabla
(-0.46 s)
[17.50 s] F1: bla bla-
(0.08 s)
[18.57 s] blaah
(-0.46 s)
[18.73 s] F2: bli bla bla bla bli bla bla
(0.47 s)
[21.05 s] F1: blabl-
(0.31 s)
[21.73 s] bla bla bla bla bla blaaaaah
|
Instructions for using the script
- Download and save the Praat script save_conversation_tiers_as_text_file.praat to a convenient location on your computer.
- Open the TextGrid file in Praat.
In case the transcripts of the different speakers are located in several different TextGrid files (the files must have an identical total duration and of course describe the very same audio recording), you must first combine those tiers that you wish to include in the transcript. In the Object window, it is possible to extract a particular tier from a TextGrid by pressing Extract tier... and providing the index number of the tier. If required, these IntervalTier objects can be renamed with the Rename button at the bottom of the Object window. (Beware of accidentally pressing the Remove button which removes the selected object(s) with no questions asked!). Next, you need to combine the IntervalTiers by selecting them together and by pressing Into TextGrid. (If this was a lot of work, you might want to save the new TextGrid object.)
- If required, rename those annotation tiers in the TextGrid that you wish to include in the transcript. Tier names will be used to identify the different speakers. Short codes with 2-3 characters are recommended. In the example, the tiers have been named with the codes F1 and F2.
The order of the tiers is not important - the utterances will be saved in the order of their starting times.
NB. The script currently works with IntervalTiers only, i.e., not with PointTiers!
- Open the Praat script save_conversation_tiers_as_text_file.praat with the command Praat:Open Praat script... in the Object window (or use Read:Read from file...).
- In the script window, select Run:Run. The following dialog box should appear:
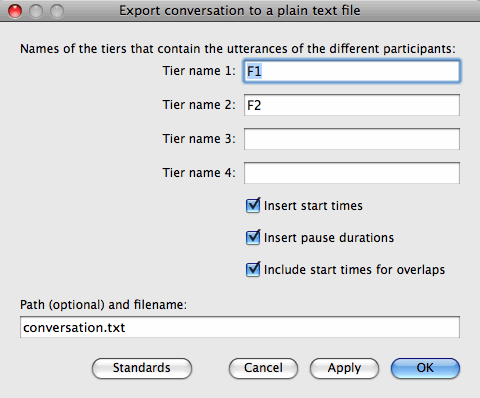
- In the four topmost fields, type the names of the tiers that you wish to export (i.e., the speaker codes). The order in which you input the tiers is not important, since each speaker's utterances will be exported in the temporal order in which they occur.
The script currently supports up to four speakers. In case there are only two speakers, for example, you should fill in the two topmost fields and leave the next two fields empty.
- In case you need a simple text file with nothing but the speaker codes and utterance transcripts, uncheck the following three checkboxes.
- If you wish the start times of each utterance to appear in front of each line (as in the above example), check Insert start times.
- If you wish the pause durations to appear between utterances (where applicable), check Insert pause durations.
A pause refers to a portion of speech after an utterance during which nobody is speaking (i.e., during which there are no labels in any of the annotation tiers).
- If you wish the overlap times to appear between utterances, check Include start times for overlaps.
The duration or start time of overlappins speech is marked as a negative figure. In case more than two speakers are simultaneously overlapping each other, the start time of overlap will be calculated as the difference between the starting point of the next utterance and the preceding overlapped utterance that started first.
- The last field (Path (optional) and filename:) should contain the filename for the transcript to be exported. The file does not need to exist, and an existing file will be overwritten. It is good practice to use the file extension .txt, since the operating system of your computer will then be able to suggest suitable programs for opening the text file.
- If there is no path but just the file name (e.g., conversation.txt), the transcript will be saved to the same directory where you saved the script file (save_conversation_tiers_as_text_file.praat). This is usually the most convenient solution.
- In case you want to provide the exact path for the transcript file, the directories in the path must exist and you must have sufficient user privileges in order for the script to succeed. If the path contains spaces, you should put it in "double quotes".
- Make sure that the TextGrid object is selected in the Object window, then press OK.
In case the TextGrid file is very long and/or if there are several speakers, it may take a while to create the transcript. When the script has finished running, the transcript should appear in the text file you asked for.
You can now use the text file as is, or you may reformat it for presentation with, e.g., MS Word. The fields in the transcript are separated by tab characters, making it even possible to open or import the file in spreadsheet programs (such as MS Excel).
NB: The script will convert the TextGrid object into the "generic" format used by Praat where special characters (e.g., phonetic symbols) are expressed as combinations of several characters ("backslash trigraphs"). This format is recommended especially when you need to open and edit the same TextGrid files in several computers and platforms (Windows/Mac/Linux). However, the script does not save the converted TextGrid object, so you need to take care of this yourself.
AND YOU'RE DONE! :-)
Please note: The Praat script described here is still being tested and may contain bugs! In case you believe the script is not working correctly or if you notice errors in the instructions below, I would be happy to receive suggestions for improvements by email. However, I cannot provide further support for using or modifying the script.
More Praat scripts